Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
😲 Segmenting objects in videos without human annotations 🤯
{kind=link}
Paper
Code and Model Weights
Presentation Video
Poster
Citation
TL;DR: Segmenting objects in videos without human annotations by Relaxed Common Fate and Visual Grouping.
Our Task
We study learning object segmentation from unlabeled videos. No human annotation is used.
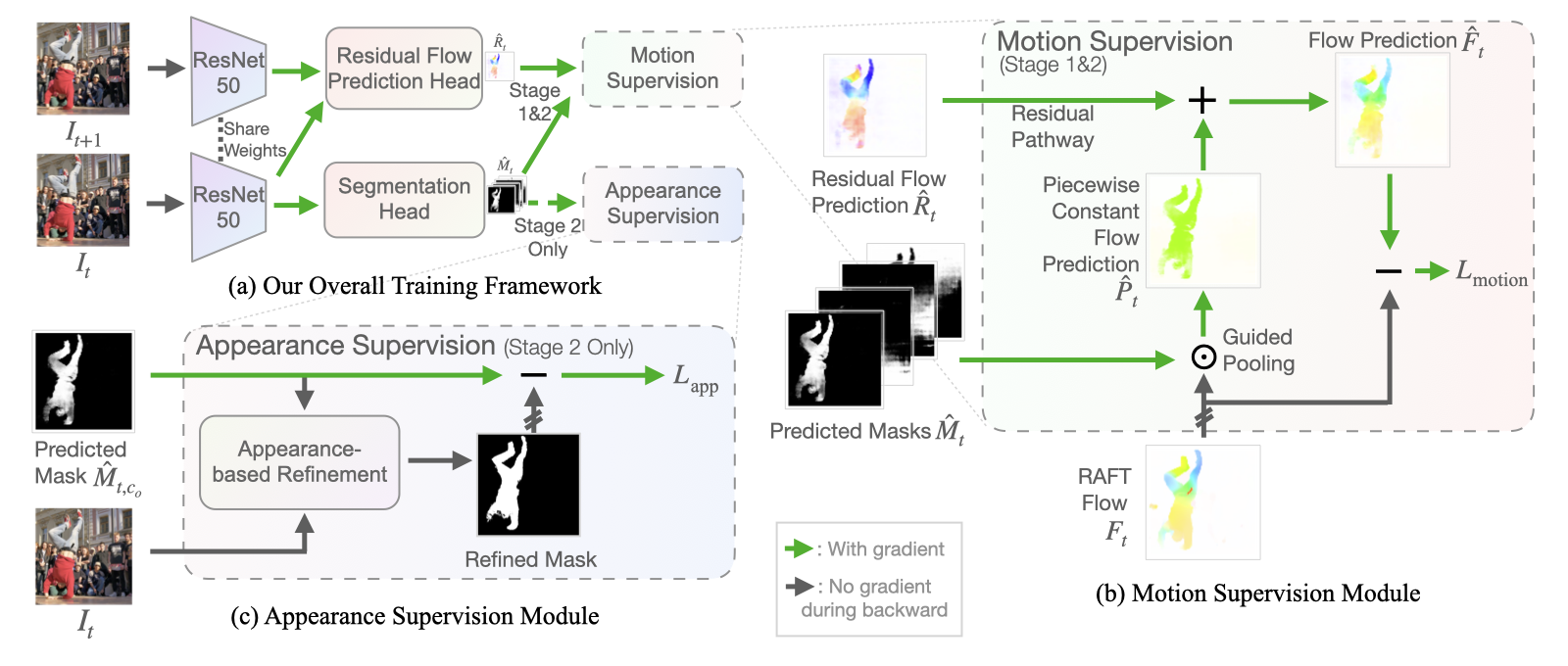
Our Framework RCF
We learn an image segmenter first in the loop of approximating optical flow with constant segment flow plus small within-segment residual flow, and then by refining it for more coherent appearance and statistical figure-ground relevance.
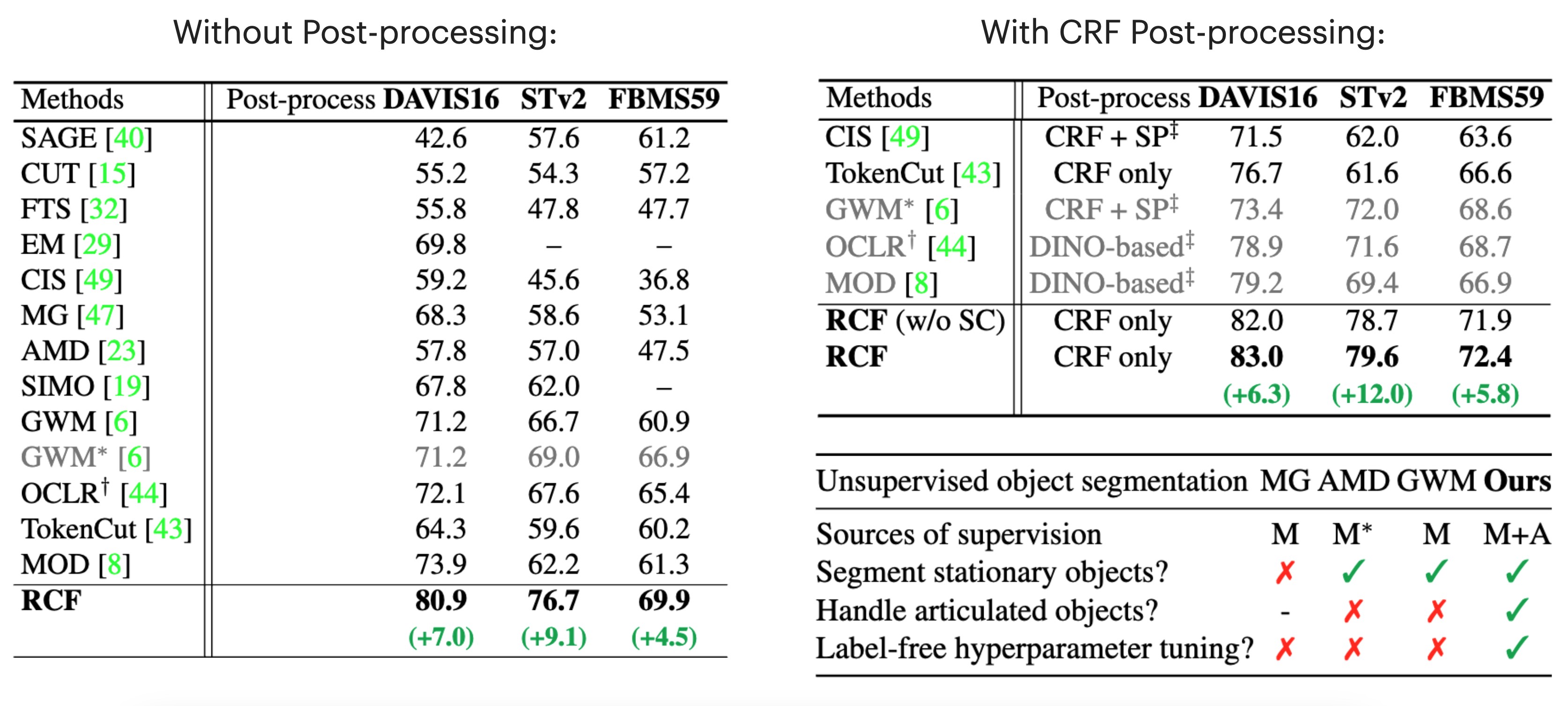
RCF's Performance
On unsupervised video object segmentation, using only ResNet and convolutional heads, our model surpasses the state-of-the-art by absolute gains of 7/9/5% on DAVIS16 / STv2 / FBMS59 respectively, demonstrating the effectiveness of our ideas.
Citation
If you use this work or find it helpful, please consider citing:
@article{lian2023bootstrapping,
title={Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping},
author={Lian, Long and Wu, Zhirong and Yu, Stella X},
journal={arXiv preprint arXiv:2304.08025},
year={2023}
}
@article{lian2022improving,
title={Improving Unsupervised Video Object Segmentation with Motion-Appearance Synergy},
author={Lian, Long and Wu, Zhirong and Yu, Stella X},
journal={arXiv preprint arXiv:2212.08816},
year={2022}
}